Глубокое обучение для NLP: создание чат-бота с помощью Python и Keras!
Узнайте, как глубокое обучение можно использовать для NLP, и создайте простого чат-бота с помощью Python и Keras. Кому не нравится дружелюбный робот-помощник?

Глубокое обучение для NLP. В предыдущем посте о LSTM мы узнали, что такое искусственные нейронные сети и глубокое обучение. Кроме того, были введены некоторые структуры нейронных сетей для использования последовательных данных, таких как текст или аудио. Если вы не читали этот пост, вам следует сесть, выпить кофе и медленно наслаждаться им.
Этот пост касался только теории, и мы знаем, что вы жаждете увидеть практику глубокого обучения для NLP. Если вам нужна более конкретная информация о NLP, например об анализе настроений, ознакомьтесь с нашей категорией учебных пособий.
В связи с этим в сегодняшней публикации будет рассказано, как использовать Keras, очень популярную библиотеку для нейронных сетей, для создания простого чат-бота. Будут объяснены основные концепции этой библиотеки, а затем мы рассмотрим пошаговое руководство о том, как использовать ее для создания бота, отвечающего да/нет, на Python. Мы будем использовать простоту Keras для реализации структуры RNN из статьи Сухбаатара и др. «Сети памяти от конца до конца» (которую вы можете найти здесь).
Это интересно, потому что, определив задачу или приложение (создав чат-бота «да/нет» для ответов на конкретные вопросы), мы узнаем, как преобразовать выводы исследовательской работы в реальную модель, которую затем можно использовать для достижения целей нашего приложения.
Не пугайтесь, если вы впервые реализуете модель NLP; Я пройдусь по каждому шагу и поставлю ссылку на код в конце. Для лучшего обучения я предлагаю вам сначала прочитать комментарий, а затем просмотреть код, просматривая разделы комментариев, которые сопровождают его.
Как только вы будете готовы, давайте приступим к делу!
Keras: простые нейронные сети в Python
Keras — это библиотека высокого уровня с открытым исходным кодом для разработки моделей нейронных сетей. Он был разработан Франсуа Шоле, исследователем глубокого обучения из Google. Его основной принцип заключается в том, чтобы сделать процесс создания нейронной сети, ее обучения и последующего использования для прогнозирования простым и доступным для всех, кто обладает базовыми знаниями в области программирования, и в то же время позволяет разработчикам полностью настраивать параметры ANN.
По сути, Keras — это просто интерфейс, который может работать поверх различных фреймворков глубокого обучения, таких как, например, CNTK, Tensorflow или Theano. Он работает одинаково, независимо от используемого бэкенда.
Как мы упоминали в предыдущем посте, в нейронной сети каждый узел на определенном уровне берет взвешенную сумму выходных данных с предыдущего уровня, применяет к ним математическую функцию, а затем передает этот результат на следующий уровень.
С помощью Keras мы можем создать блок, представляющий каждый слой, где можно легко определить эти математические операции и количество узлов в слое. Эти разные слои можно создать, набрав интуитивно понятную строку кода.
Чтобы создать модель Keras, выполните следующие действия:
Шаг 1. Сначала мы должны определить модель сети, которая в большинстве случаев будет последовательной моделью: сеть будет определена как последовательность слоев, каждый из которых имеет свой собственный настраиваемый размер и функцию активации. В этих моделях первым слоем будет входной слой, который требует от нас определения размера входных данных, которые мы будем подавать в сеть. После этого можно добавлять и настраивать все больше и больше слоев, пока мы не достигнем окончательного выходного слоя.
#Задайте последовательную модель
model = Sequential()
#Создать входной слой
model.add(Dense(32, input_dim=784))
#Создать скрытый слой
model.add(Activation('relu'))
#Создать выходной слой
model.add(Activation('sigmoid')) Шаг 2: После создания структуры сети таким образом мы должны ее скомпилировать, что преобразует простую последовательность слоев, которую мы ранее определили, в сложную группу матричных операций, которые определяют поведение сети. Здесь мы должны определить алгоритм оптимизации, который будет использоваться для обучения сети, а также выбрать функцию потерь, которая будет минимизирована.
#Составление модели со среднеквадратичной ошибкой потерь и RMSProp #опмтимизатора
model.compile(optimizer='rmsprop',loss='mse')Шаг 3. Как только это будет сделано, мы можем обучить или настроить сеть, что делается с использованием алгоритма обратного распространения, упомянутого в предыдущем посте.
#Обучите модель, перебирая данные партиями по 32 выборки.
model.fit(data, labels, epochs=10, batch_size=32)Шаг 4. Ура! Наша сеть обучена. Теперь мы можем использовать его для прогнозирования новых данных.
Как видите, построить сеть с помощью Keras довольно просто, поэтому давайте приступим к ней и используем ее для создания нашего чат-бота! Блоки кода, используемые выше, не являются репрезентативными для реальной конкретной модели нейронной сети, они являются просто примерами каждого из шагов, которые помогают проиллюстрировать, насколько просто построить нейронную сеть с использованием API Keras.
Вы можете найти всю документацию о Keras и о том, как его установить, на его официальной веб-странице.
Проект: использование рекуррентных нейронных сетей для создания чат-бота
Теперь мы знаем, что такое все эти различные типы нейронных сетей, давайте используем их для создания чат-бота, который может ответить на некоторые вопросы!
В большинстве случаев структуры нейронных сетей более сложны, чем просто стандартный ввод-скрытый слой-вывод. Иногда мы можем сами изобрести нейронную сеть и поэкспериментировать с различными комбинациями узлов или слоев. Кроме того, в некоторых случаях нам может понадобиться реализовать модель, которую мы где-то видели, например, в научной статье.
В этом посте мы рассмотрим пример этого второго случая и построим нейронную модель из статьи Сухбаатара и др. «End to End Memory Networks» (которую вы можете найти здесь).
Также мы увидим, как сохранить обученную модель, чтобы нам не приходилось обучать сеть каждый раз, когда мы хотим делать прогнозы, используя построенную нами модель. Тогда поехали!
Модель: Вдохновение
Как упоминалось ранее, RNN, используемая в этом посте, была взята из статьи «End to End Memory Networks», поэтому я рекомендую вам ознакомиться с ней, прежде чем продолжить, хотя я объясню наиболее важные части в следующих строках.
В этой статье реализована структура, подобная RNN, которая использует модель внимания для компенсации проблемы долговременной памяти, связанной с RNN, которую мы обсуждали в предыдущем посте.
Не знаете, что такое модель внимания? Не волнуйтесь, мы объясним вам это простыми словами. Модели внимания вызвали большой интерес из-за их очень хороших результатов в таких задачах, как машинный перевод. Они решают проблему длинных последовательностей и кратковременной памяти RNN, о которой упоминалось ранее.
Чтобы получить интуитивное представление о том, что делает внимание, подумайте о том, как человек перевел бы длинное предложение с одного языка на другой. Вместо того, чтобы брать предложение, а затем переводить его за один раз, вы разбиваете предложение на более мелкие фрагменты и переводите эти более мелкие фрагменты один за другим. Мы работаем по частям с предложением, потому что действительно сложно запомнить его целиком, а затем сразу перевести. Это один из многих изящных приемов глубокого обучения для NLP.

Механизм внимания делает именно это. На каждом временном шаге модель придает больший вес в выходных данных тем частям входного предложения, которые в большей степени относятся к задаче, которую мы пытаемся выполнить. Отсюда и название: оно обращает внимание на то, что важнее. Приведенный выше пример очень хорошо это иллюстрирует; чтобы перевести первую часть предложения, нет смысла смотреть на все предложение или на последнюю часть предложения.
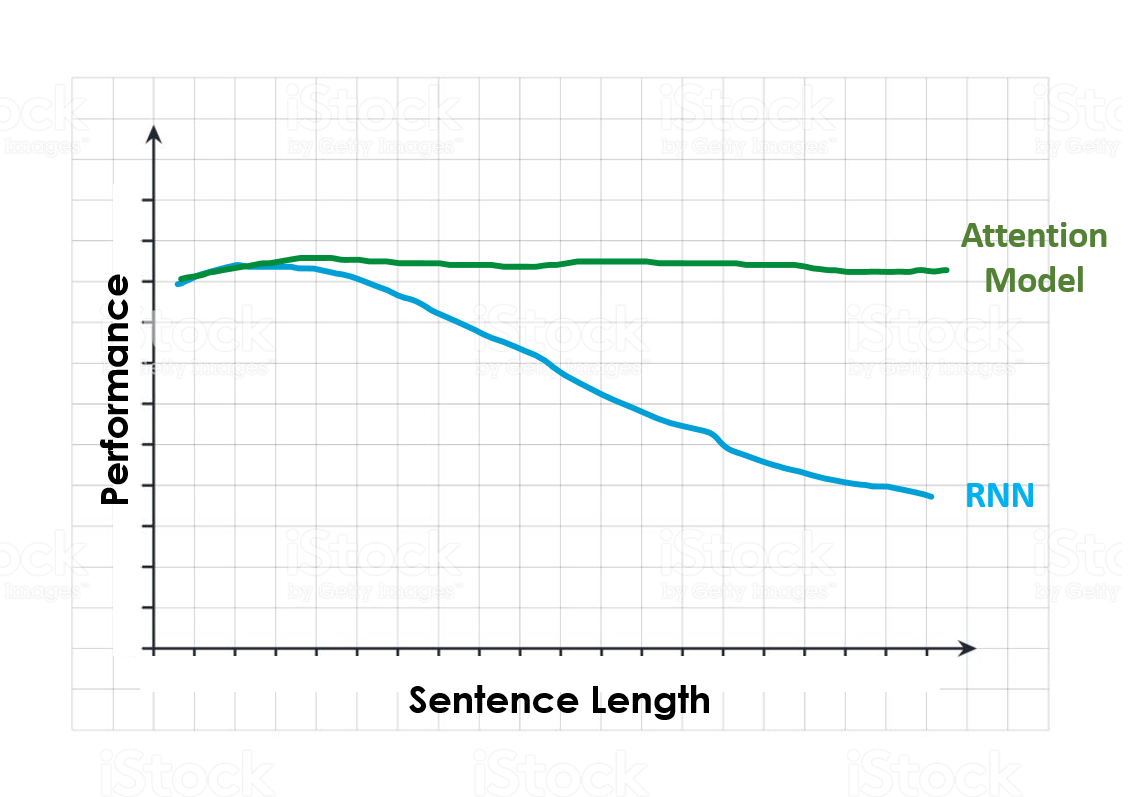
На следующем рисунке показана производительность моделей RNN и Attention при увеличении длины входного предложения. Столкнувшись с очень длинным предложением и попросив выполнить конкретную задачу, RNN после обработки всего предложения, вероятно, забудет о первых входных данных, которые у нее были.
Хорошо, теперь, когда мы знаем, что такое модель внимания, давайте взглянем на структуру модели, которую мы будем использовать. Эта модель принимает ввод xi (предложение), запрос q о таком предложении и выводит ответ a: да/нет.
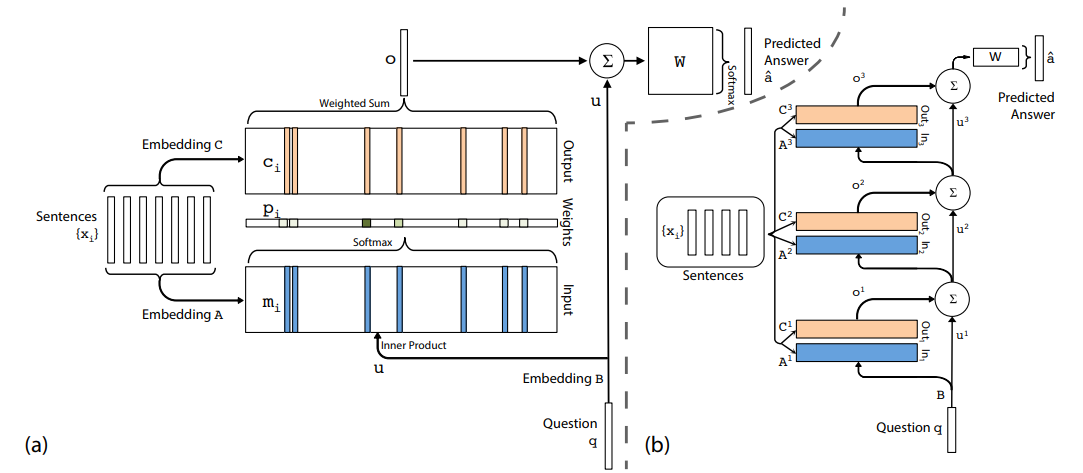
В левой части предыдущего изображения мы видим представление одного слоя этой модели. Для каждого предложения рассчитываются два разных вложения: A и C. Кроме того, запрос или вопрос q встраивается с использованием вложения B.
Вложения A mi затем вычисляются с использованием скалярного произведения с вопросом, встраивающим u (это та часть, где имеет место внимание, поскольку, вычисляя внутреннее произведение между этими вложениями, мы ищем совпадения слов из запрос и предложение, чтобы затем придать большее значение этим совпадениям с помощью функции Softmax на результирующих терминах скалярного произведения).
Наконец, мы вычисляем выходной вектор o, используя вложения из C (ci) и веса или вероятности pi, полученные из скалярного произведения. С этим выходным вектором o, матрицей весов W и вложением вопроса u мы наконец можем вычислить предсказанный ответ a hat.
Чтобы построить всю сеть, мы просто повторяем эту процедуру на разных слоях, используя предсказанные выходные данные одного из них в качестве входных данных для следующего. Это показано в правой части предыдущего изображения.
Не беспокойтесь, если все это пришло к вам слишком быстро, надеюсь, вы получите лучшее и полное понимание, когда мы пройдем различные этапы реализации этой модели в Python, чтобы применить наши знания глубокого обучения для NLP на практике!
Данные: истории, вопросы и ответы
В 2015 году Facebook разработал набор данных bAbI и 20 заданий для проверки понимания текста и рассуждений в рамках проекта bAbI. Задачи подробно описаны в статье здесь.
Цель каждой задачи – бросить вызов уникальному аспекту деятельности, связанной с машинным текстом, и протестировать различные возможности моделей обучения. В этом посте мы столкнемся с одной из этих задач, а именно с «QA с одним подтверждающим фактом».
В приведенном ниже блоке показан пример ожидаемого поведения бота QA такого типа:
ФАКТ: Сандра вернулась в коридор. Сандра переехала в офис. ВОПРОС: Сандра в офисе? ОТВЕТ: да
Набор данных уже разделен на обучающие данные (10 тыс. экземпляров) и тестовые данные (1 тыс. экземпляров), где у каждого экземпляра есть факт, вопрос и ответ «да/нет» на этот вопрос.
Теперь, когда мы увидели структуру наших данных, нам нужно составить из них словарь. В модели обработки естественного языка словарь представляет собой набор слов, которые модель знает и, следовательно, может понять. Если после построения словаря модель увидит внутри предложения слово, которого нет в словаре, она либо присвоит ему значение 0 на своих векторах предложений, либо представит его как неизвестное.
VOCABULARY: '.', '?', 'Daniel', 'Is', 'John', 'Mary', 'Sandra', 'apple','back','bathroom', 'bedroom', 'discarded', 'down','dropped','football', 'garden', 'got', 'grabbed', 'hallway','in', 'journeyed', 'kitchen', 'left', 'milk', 'moved','no', 'office', 'picked', 'put', 'the', 'there', 'to','took', 'travelled', 'up', 'went', 'yes'
Поскольку наши данные для обучения не очень разнообразны (в большинстве вопросов используются одни и те же глаголы и существительные, но с разными комбинациями), наш словарный запас не очень велик, но в проектах NLP среднего размера словарный запас может быть очень большим.
Учтите, что для создания словаря большую часть времени мы должны использовать только обучающие данные; тестовые данные следует отделить от обучающих данных в самом начале проекта машинного обучения и не трогать до тех пор, пока не придет время оценить производительность выбранной и настроенной модели.
После создания словаря нам нужно векторизовать наши данные. Поскольку мы используем обычные слова в качестве входных данных для наших моделей, а компьютеры могут работать только с числами под капотом, нам нужен способ представлять наши предложения, которые представляют собой группы слов, в виде векторов чисел. Векторизация делает именно это.
Существует много способов векторизации наших предложений, таких как модели Bag of Words или Tf-Idf, однако для простоты мы собираемся просто использовать метод векторизации с индексированием, в котором каждому слову в словаре присваивается уникальный индекс. от 1 до длины словаря.
VECTORIZATION INDEX: 'the': 1, 'bedroom': 2, 'bathroom': 3, 'took': 4, 'no': 5, 'hallway': 6, '.': 7, 'went': 8, 'is': 9, 'picked': 10, 'yes': 11, 'journeyed': 12, 'back': 13, 'down': 14, 'discarded': 15, 'office': 16, 'football': 17, 'daniel': 18, 'travelled': 19, 'mary': 20, 'sandra': 21, 'up': 22, 'dropped': 23, 'to': 24, '?': 25, 'milk': 26, 'got': 27, 'in': 28, 'there': 29, 'moved': 30, 'garden': 31, 'apple': 32, 'grabbed': 33, 'kitchen': 34, 'put': 35, 'left': 36, 'john': 37}
Учтите, что эта векторизация выполняется с использованием случайного начального числа, поэтому, даже если вы используете те же данные, что и я, вы можете получить разные индексы для каждого слова. Не волнуйся; это не повлияет на результаты проекта. Кроме того, слова в нашем лексиконе были в верхнем и нижнем регистре; при выполнении этой векторизации все слова для единообразия переводятся в нижний регистр.
После этого, из-за того, как работает Keras, нам нужно дополнить предложения. Что это значит? Это означает, что нам нужно найти длину самого длинного предложения, преобразовать каждое предложение в вектор этой длины и заполнить пробел между количеством слов в каждом предложении и количеством слов в самом длинном предложении нулями.
После этого случайное предложение набора данных должно выглядеть так:
FIRST TRAINING SENTENCE VECTORIZED AND PADDED:
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 20, 30, 24, 1, 3, 7, 21, 12, 24, 1, 2, 7])Как мы видим, в нем везде есть нули, кроме конца (это предложение было намного короче самого длинного предложения), где есть числа. Что это за числа? Ну, это индексы, представляющие разные слова в предложении: 20 — это индекс, представляющий слово «Мэри», 30 — «перемещено», 24 — «к», 1 — «то», 3 — «ванная» и так далее. Фактическое предложение:
FIRST TRAINING SENTENCE: "Mary moved to the bathroom . Sandra journeyed to the bedroom ."
Хорошо, теперь, когда мы подготовили данные, мы готовы построить нашу нейронную сеть!
Глубокое обучение для NLP: нейронная сеть и построение модели
Первым шагом к созданию сети является создание того, что в Керасе известно как заполнители для входных данных, которыми в нашем случае являются истории и вопросы. Проще говоря, эти заполнители представляют собой контейнеры, в которые будут помещены пакеты наших обучающих данных перед их подачей в модель.
#Пример заполнителя
question = Input((max_question_len,batch_size))Они должны иметь то же измерение, что и данные, которые будут переданы, а также может иметь определенный размер пакета, хотя мы можем оставить его пустым, если мы не знаем его во время создания заполнителей.
Теперь нам нужно создать вложения, упомянутые в статье, A, C и B. Вложение превращает целое число (в данном случае индекс слова) в d-мерный вектор, где учитывается контекст. Встраивание слов широко используется в НЛП и является одним из методов, благодаря которым эта область значительно продвинулась в последние годы.
#Создайте кодировщик ввода A:
input_encoder_m = Sequential()
input_encoder_m.add(Embedding(input_dim=vocab_len,output_dim = 64))
input_encoder_m.add(Dropout(0.3)) #На выходе: (Samples, story_maxlen,embedding_dim) -- Дает список #длины выборок, где каждый
элемент имеет
#длина максимальной длины истории, и каждое слово встроено в размер
внедренияПриведенный выше код является примером одного из вложений, сделанных в статье (вложение A). Как всегда в Keras, мы сначала определяем модель (последовательную), а затем добавляем слой внедрения и слой исключения, что снижает вероятность переобучения модели за счет отключения узлов сети.
После того, как мы создали два вложения для входных предложений и вложения для вопросов, мы можем начать определять операции, которые происходят в нашей модели. Как упоминалось ранее, мы вычисляем внимание, выполняя скалярное произведение между встраиванием вопросов и одним из вложений историй, а затем выполняя softmax. В следующем блоке показано, как это делается:
match = dot([input_encoded_m,question_encoded], axes = (2,2))
match = Activation('softmax')(match)После этого нам нужно вычислить результат добавления матрицы соответствия ко второй последовательности входных векторов, а затем вычислить ответ, используя этот вывод и закодированный вопрос.
response = add([match,input_encoded_c])
response = Permute((2,1))(response)
answer = concatenate([response, question_encoded])Наконец, как только это будет сделано, мы добавим остальные слои модели, добавив слой LSTM (вместо RNN, как в документе), слой отсева и окончательный softmax для вычисления выходных данных.
answer = LSTM(32)(answer)
answer = Dropout(0.5)(answer)
#Output layer:
answer = Dense(vocab_len)(answer)
#Output shape: (Samples, Vocab_size) #Yes or no and all 0s
answer = Activation('softmax')(answer)Обратите внимание, что выход представляет собой вектор размера словаря (то есть длины количества слов, известных модели), где все позиции должны быть нулевыми, кроме позиций с индексами «да» и «нет».
Глубокое обучение для NLP: изучение данных и обучение модели
Теперь мы готовы скомпилировать модель и обучить ее!
model = Model([input_sequence,question], answer)
model.compile(optimizer='rmsprop', loss = 'categorical_crossentropy',
metrics = ['accuracy'])С помощью этих двух строк мы строим окончательную модель и компилируем ее, то есть определяем всю математику, которая будет выполняться в фоновом режиме, указав оптимизатор, функцию потерь и метрику для оптимизации.
Теперь пришло время обучить модель, здесь нам нужно определить входные данные для обучения (входные истории, вопросы и ответы), размер пакета, которым мы будем снабжать модель (то есть, сколько входных данных одновременно) и количество эпох, для которых мы будем обучать модель (то есть, сколько раз модель будет проходить данные обучения, чтобы обновить веса). Я использовал 1000 эпох и получил точность 98%, но даже при 100-200 эпохах вы должны получить довольно хорошие результаты.
Обратите внимание, что в зависимости от вашего оборудования это обучение может занять некоторое время. Просто расслабьтесь, откиньтесь на спинку кресла, продолжайте читать и подождите, пока это не будет сделано.
После завершения обучения у вас может возникнуть вопрос: «Мне придется так долго ждать каждый раз, когда я хочу использовать модель?» очевидный ответ, мой друг, НЕТ. Keras позволяет разработчикам сохранять определенную обученную модель с весами и всеми конфигурациями. Следующий блок кода показывает, как это делается.
filename = 'medium_chatbot_1000_epochs.h5'
model.save(filename)Теперь, когда мы хотим использовать модель, достаточно просто загрузить ее следующим образом:
model.load_weights('medium_chatbot_1000_epochs.h5')Классно классно. Теперь, когда мы обучили нашу модель с помощью глубокого обучения для NLP, давайте посмотрим, как она работает с новыми данными, и немного поиграем с ней!
Видим результаты: тестируем и играем
Давайте посмотрим, как наш чат-бот в модели Python и Keras работает с тестовыми данными!
pred_results = model.predict(([inputs_test,questions_test]))Эти результаты представляют собой массив, как упоминалось ранее, который содержит в каждой позиции вероятности того, что каждое из слов в словаре является ответом на вопрос. Если мы посмотрим на первый элемент этого массива, мы увидим вектор размера словаря, где все времена близки к 0, кроме тех, которые соответствуют да или нет.
Из них, если мы выберем индекс наибольшего значения массива, а затем посмотрим, какому слову он соответствует, мы должны выяснить, является ли ответ утвердительным или отрицательным.
Одна забавная вещь, которую мы можем сделать сейчас, – это создавать свои собственные истории и вопросы и передавать их боту, чтобы увидеть, что он говорит!
my_story = 'Sandra picked up the milk . Mary travelled left . '
my_story.split()
my_question = 'Sandra got the milk ?'
my_question.split()Я создал историю и вопрос, чем-то похожие на то, что наш маленький бот видел раньше, и после адаптации его к формату, который хочет нейросеть, бот ответил «ДА» (в нижнем регистре жестко, он не так воодушевлен, как я) .
Давайте попробуем с чем-то другим:
my_story = 'Nerd IT is cool . Everybody likes it. '
my_story.split()
my_question = 'Do people like Nerd IT?'
my_question.split()На этот раз ответ был: «Конечно, а кто нет?»
Шучу, я не пробовал эту комбинацию рассказ/вопрос, так как многие включенные слова не входят в словарь нашего маленького автоответчика. Кроме того, он умеет только говорить «да» и «нет» и обычно не дает никаких других ответов. Однако с большим количеством обучающих данных и некоторыми обходными путями этого можно было бы легко достичь.
Вот и все на сегодня! Мы надеемся, что вам, ребята, понравился этот пост о глубоком обучении для NLP, так же, как нам понравилось его писать.