Глубокое обучение для NLP: объяснение ANN, RNN и LSTM!
Узнайте об искусственных нейронных сетях, глубоком обучении, рекуррентных нейронных сетях и LSTM, как никогда раньше, и используйте NLP для создания чат-бота на Python!

Вы когда-нибудь мечтали о том, чтобы у вас был личный помощник, который отвечал бы на любые вопросы, которые вы могли бы задать или пообщаться? Что ж, благодаря машинному обучению и глубоким нейронным сетям это не так уж и далеко от реальности. Подумайте об удивительных возможностях Siri от Apple или Alexa от Amazon. В этой статье мы увидим, как работают глубокие нейронные сети, наряду с наиболее важными семействами для работы с текстом, рекуррентными нейронными сетями и сетями с долговременной кратковременной памятью или LSTM.
Не волнуйтесь, в этой серии постов мы не собираемся создавать всемогущий искусственный интеллект, а скорее создадим простого чат-бота на Python, который получает некоторую входную информацию и вопрос о такой информации, отвечает да/нет на вопросы относительно того, что было сказано.
Это далеко от возможностей Siri или Алисы, но очень хорошо иллюстрирует, как даже с использованием очень простых структур глубокой нейронной сети можно получить потрясающие результаты. В этом посте мы узнаем об искусственных нейронных сетях, глубоком обучении, рекуррентных нейронных сетях и сетях долговременной памяти. В следующем посте мы будем использовать их в реальном проекте, чтобы сделать бота, отвечающего на вопросы.
Прежде чем мы начнем со всего интересного, связанного с нейронными сетями, я хочу, чтобы вы сначала внимательно посмотрели на следующее изображение. В нем две картинки; один из школьного автобуса, едущего по дороге, и один из обычной гостиной, описания которой были добавлены комментаторами-людьми.

Готовы? Тогда давайте продолжим!
Основы — искусственные нейронные сети (ANN)
Для построения модели нейронной сети, которая будет использоваться для создания чат-бота, Keras, будет использоваться очень популярная библиотека Python для нейронных сетей. Однако, прежде чем идти дальше, мы сначала должны понять, что такое искусственная нейронная сеть (Artificial Neural Network) или ANN.
ANN — это модели машинного обучения, которые пытаются имитировать работу человеческого мозга, структура которого построена из большого количества нейронов, соединенных между собой — отсюда и название «Искусственные нейронные сети».
Персептрон
Простейшая модель ANN состоит из одного нейрона и носит название «Персептрон», звучащее как из «Звездного пути». Он был изобретен в 1957 году Фрэнком Россенблаттом и состоит из простого нейрона, который принимает взвешенную сумму своих входов (которые в биологическом нейроне были бы дендритами), применяет к ним математическую функцию и выводит свой результат (выходной сигнал, который будет эквивалентом аксона биологического нейрона). Мы не будем углубляться в детали различных функций, которые можно здесь применить, так как цель поста не в том, чтобы стать экспертом, а в том, чтобы получить общее представление о том, как работает нейронная сеть.
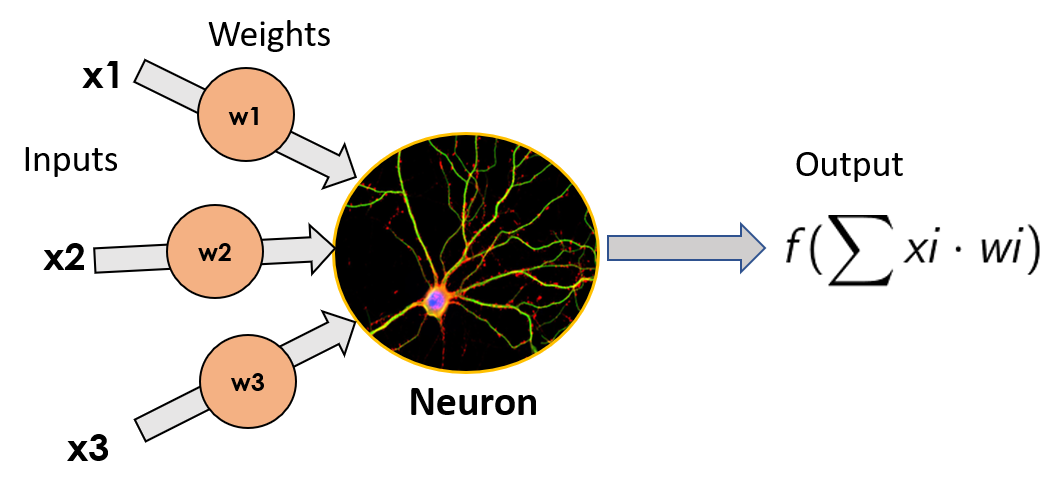
Эти отдельные нейроны можно накладывать друг на друга, образуя слои нужного нам размера, а затем эти слои можно последовательно размещать рядом друг с другом, чтобы сделать сеть глубже.
Когда сети построены таким образом, нейроны, не принадлежащие входному или выходному слою, считаются частью скрытых слоев, отражая своим названием одну из основных характеристик ANN: они являются почти моделями черного ящика; мы понимаем математику, стоящую за тем, что происходит, и отчасти имеем интуицию о том, что происходит внутри черного ящика, но если мы возьмем выходные данные скрытого слоя и попытаемся разобраться в этом, мы, вероятно, сломаем голову.
Тем не менее, они дают потрясающие результаты, так что никто не жалуется на их отсутствие интерпретации.
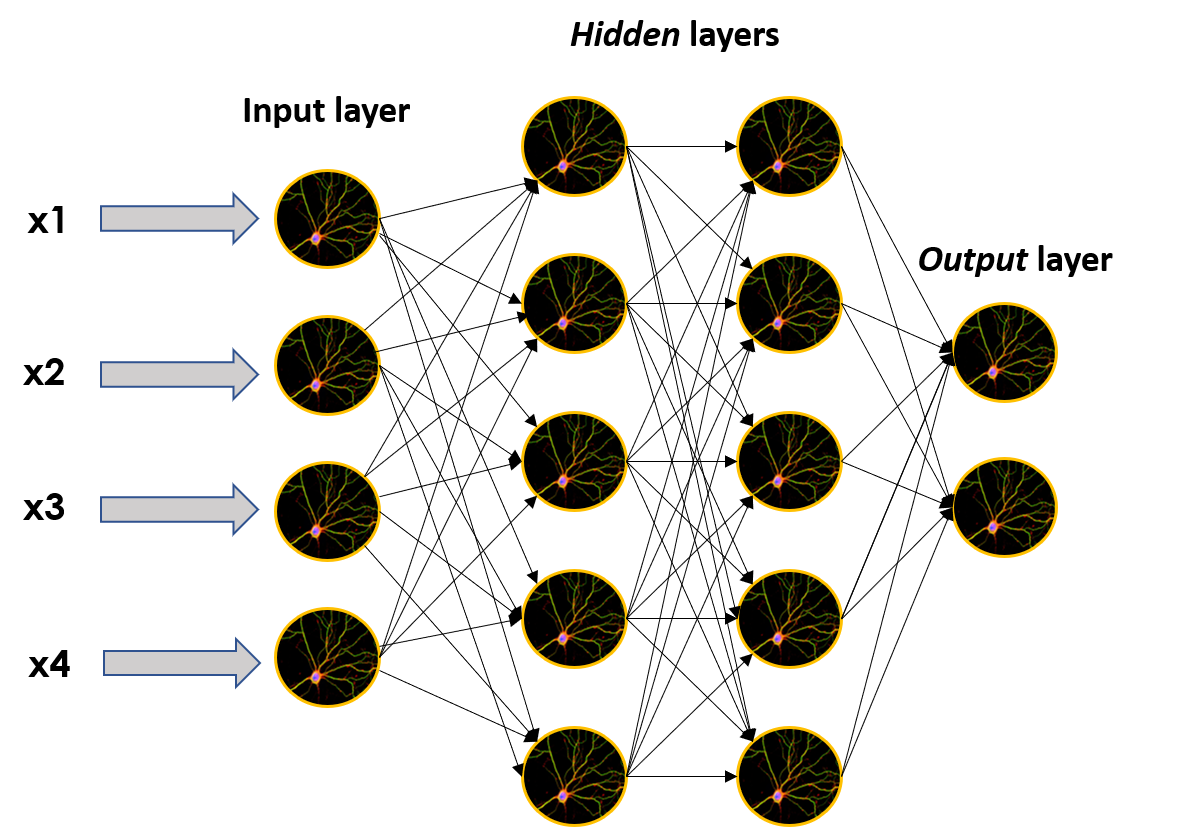
Нейросетевые структуры и способы их обучения известны уже более двух десятилетий. Что же тогда привело к суматохе и ажиотажу вокруг ANN и глубокого обучения, которые происходят прямо сейчас? Ответ на этот вопрос чуть ниже, но прежде мы должны понять, что такое глубокое обучение на самом деле.
Что же такое глубокое обучение?
Глубокое обучение, как вы можете догадаться по названию, — это просто использование множества слоев для постепенного извлечения признаков более высокого уровня из данных, которые мы передаем в нейронную сеть. Это так просто; использование нескольких скрытых слоев для повышения производительности наших нейронных моделей.
Теперь, когда мы это знаем, ответ на поставленный выше вопрос довольно прост: масштаб. За последние два десятилетия количество доступных данных всех видов и мощность наших машин для хранения и обработки данных (да, компьютеров) выросли в геометрической прогрессии.
Эти вычислительные возможности и значительное увеличение объема доступных данных для обучения наших моделей позволили нам создавать более крупные и глубокие нейронные сети, которые просто работают лучше, чем более мелкие.

Для традиционных алгоритмов машинного обучения (линейная или логистическая регрессия, SMV, случайные леса и т. д.) производительность увеличивается по мере того, как мы обучаем модели с большим количеством данных, до определенного момента, когда производительность перестает расти, когда мы загружаем модель дополнительными данными. . Когда эта точка достигнута, похоже, что модель не знает, что делать с дополнительными данными, и ее производительность больше не может быть улучшена путем подачи большего количества данных.
С другой стороны, с нейронными сетями этого никогда не происходит. Производительность почти всегда увеличивается с данными (если эти данные хорошего качества, конечно), и это происходит быстрее в зависимости от размера сети. Поэтому, если мы хотим получить максимально возможную производительность, нам нужно быть где-то на зеленой линии (большая нейронная сеть) и справа от оси X (большой объем данных).
Помимо этого, также произошли некоторые алгоритмические улучшения, но главный факт, который привел к великолепному росту глубокого обучения и искусственных нейронных сетей, — это просто масштаб: масштаб вычислений и масштаб данных.
Еще одна важная личность в этой области, Джефф Дин (один из инициаторов внедрения глубокого обучения в Google), говорит о глубоком обучении следующее:
Когда вы слышите термин «глубокое обучение», просто подумайте о большой глубокой нейронной сети. Глубокий обычно относится к количеству слоев, поэтому это популярный термин, принятый в прессе. Я думаю о них как о глубоких нейронных сетях в целом.
Говоря о глубоком обучении, он подчеркивает масштабируемость нейронных сетей, указывая на то, что результаты улучшаются с увеличением количества данных и более крупных моделей, которые, в свою очередь, требуют больше вычислений для обучения, как мы видели раньше.
Хорошо, я все понял, но как на самом деле учатся нейронные сети?
Что ж, вы, наверное, уже догадались: они учатся на данных.
Помните веса, которые умножали наши входные данные в один персептрон? Ну, эти веса также включены в любое ребро, соединяющее два разных нейрона. Это означает, что на изображении более крупной нейронной сети они присутствуют в каждом из черных краев, берут выходные данные одного нейрона, умножают их, а затем передают в качестве входных данных другому нейрону, к которому подключено это ребро.
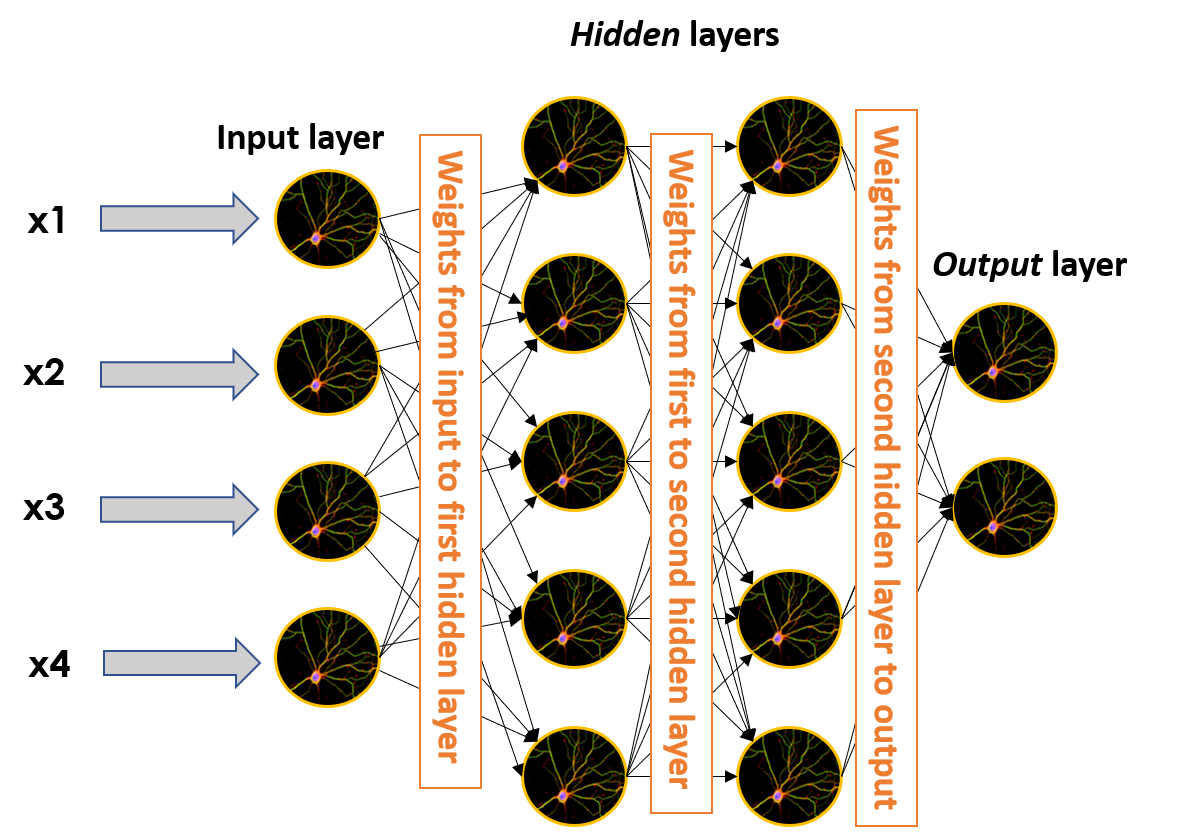
Когда мы обучаем нейронную сеть (обучение нейронной сети — это выражение ML для ее обучения), мы передаем ей набор известных данных (в ML это называется помеченными данными), чтобы она предсказывала характеристику, которую мы знаем о таких данных ( например, если изображение представляет собаку или кошку), а затем сравните прогнозируемый результат с фактическим результатом.
По мере того как этот процесс продолжается и сеть совершает ошибки, она адаптирует веса связей между нейронами, чтобы уменьшить количество совершаемых ошибок. Из-за этого, как показано ранее, если мы будем давать сети все больше и больше данных, большую часть времени это улучшит ее производительность.
Обучение на последовательных данных — рекуррентные нейронные сети. Объяснение предшественников LSTM
Теперь, когда мы знаем, что такое искусственные нейронные сети и глубокое обучение, и имеем небольшое представление о том, как нейронные сети обучаются, давайте начнем рассматривать тип сетей, которые мы будем использовать для создания нашего чат-бота: Рекуррентные нейронные сети или RNN для краткости.
Рекуррентные нейронные сети — это особый вид нейронных сетей, предназначенных для эффективной работы с последовательными данными. К таким данным относятся временные ряды (список значений некоторых параметров за определенный период времени), текстовые документы, которые можно рассматривать как последовательность слов, или аудио, которые можно рассматривать как последовательность звуковых частот.
Способ, которым RNN делают это, заключается в том, что они берут выходные данные каждого нейрона и возвращают их ему в качестве входных данных. Делая это, он не только получает новые фрагменты информации на каждом временном шаге, но также добавляет к этим новым фрагментам информации взвешенную версию предыдущего вывода. Это заставляет эти нейроны иметь своего рода «память» о предыдущих входных данных, которые они имели, поскольку они каким-то образом количественно определяются выходными данными, возвращаемыми нейрону.
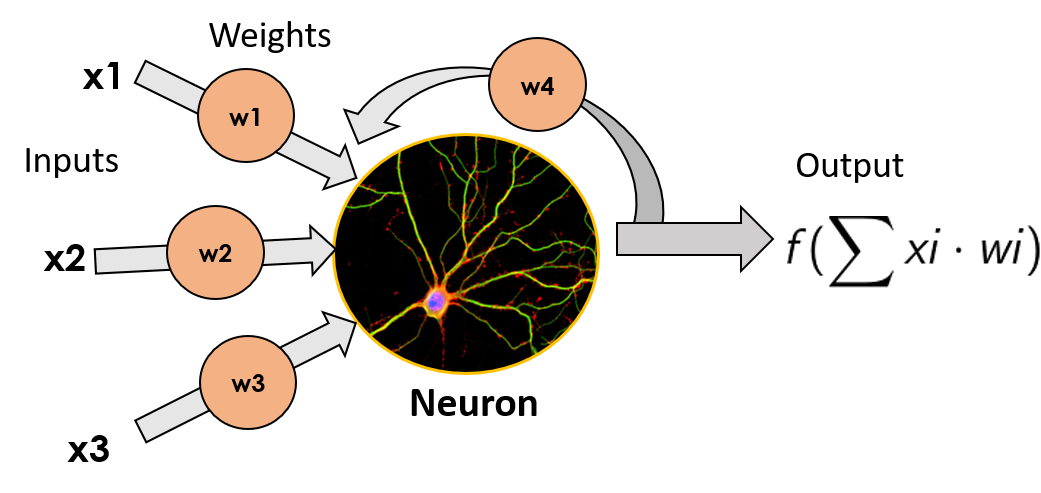
Ячейки, которые являются функцией входных данных из предыдущих временных шагов, также известны как ячейки памяти.
Проблема с RNN заключается в том, что по прошествии времени, когда они получают все больше и больше новых данных, они начинают «забывать» о предыдущих данных, которые они видели, поскольку они разбавляются между новыми данными, преобразованием из функции активации и умножение веса. Это означает, что у них хорошая кратковременная память, но есть небольшая проблема при попытке вспомнить то, что произошло некоторое время назад (данные, которые они видели во многих временных промежутках в прошлом).
Нам нужна какая-то долговременная память, которую и обеспечивают LSTM.
Улучшение нашей памяти — сети долговременной кратковременной памяти(Long Short Term Memory Networks): объяснение LSTM
Сети с долговременной памятью или LSTM – это разновидность RNN, которая решает проблему долговременной памяти первой. Мы закончим этот пост кратким объяснением LSTM.
У них более сложная клеточная структура, чем у обычного рекуррентного нейрона, что позволяет им лучше регулировать, как учиться или забывать из различных источников входных данных.

Нейрон LSTM может сделать это, включив состояние ячейки и три разных ворот: входные ворота, ворота забывания и выходные ворота. На каждом временном шаге ячейка может решить, что делать с вектором состояния: читать из него, записывать в него или удалять его благодаря явному механизму стробирования. С помощью входных ворот ячейка может решить, обновлять состояние ячейки или нет. С воротами забывания ячейка может стереть свою память, а с воротами вывода ячейка может решить, делать ли выходную информацию доступной или нет.
LSTM также смягчают проблемы взрывающихся и исчезающих градиентов, но это история для другого дня.
Вот и все! Теперь у нас есть поверхностное представление о том, как работают эти различные типы нейронных сетей, и мы можем использовать его для создания нашего первого проекта глубокого обучения!
Выводы
Нейронные сети — это круто. Как мы увидим в следующем посте, даже очень простая структура с несколькими слоями может создать очень компетентного чат-бота.
О, и кстати, помните это изображение?

Ну, просто чтобы доказать, насколько круты Deep Neural Networks, мы должны кое-что признать. Мы солгали о том, как создавались описания изображений.
В начале поста я сказал, что эти описания были сделаны людьми-аннотаторами, однако правда в том, что эти короткие тексты, описывающие то, что можно увидеть на каждом изображении, на самом деле были созданы искусственной нейронной сетью.
Безумие, верно?
Если вы хотите узнать, как использовать Deep Learning для создания отличного чат-бота, прочтите следующий пост.