Streamlit - инструмент для быстрого прототипирования
Streamlit - это мощный инструмент, который позволяет легко создавать интерактивные приложения для анализа данных и машинного обучения.

Привет всем! Сегодня я хочу поделиться своим опытом работы со Streamlit и рассказать, как этот инструмент может помочь вам в анализе данных и машинном обучении.
Streamlit - это невероятно простой и мощный фреймворк на Python для создания интерактивных веб-приложений, ориентированных на данные. Он позволяет буквально за считанные минуты превращать ваши скрипты на Python в удобные веб-интерфейсы, что особенно полезно для специалистов по данным и исследователей.
Основные преимущества Streamlit
- Простота использования: Вам не нужно быть веб-разработчиком, чтобы создать приложение. Все, что вам нужно, это знание Python.
- Быстрая визуализация: Streamlit позволяет быстро отображать графики, таблицы и другие визуализации.
- Интерактивность: Вы можете добавлять интерактивные элементы, такие как слайдеры, кнопки и выпадающие списки, чтобы пользователи могли взаимодействовать с вашими данными в реальном времени.
- Интеграция с популярными библиотеками: Streamlit отлично работает с такими библиотеками, как Pandas, NumPy, Matplotlib, Plotly, и многими другими.
Пример использования Streamlit для анализа данных
Давайте создадим простое приложение для анализа набора данных о бриллиантах. Мы будем использовать Pandas для манипулирования данными и Plotly для визуализации.
- Установите Streamlit:
pip install streamlit
- Создайте файл
app.pyи добавьте следующий код:
import streamlit as st
import pandas as pd
import plotly.express as px
# Загружаем данные
@st.cache
def load_data():
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/diamonds.csv"
data = pd.read_csv(url)
return data
data = load_data()
# Заголовок приложения
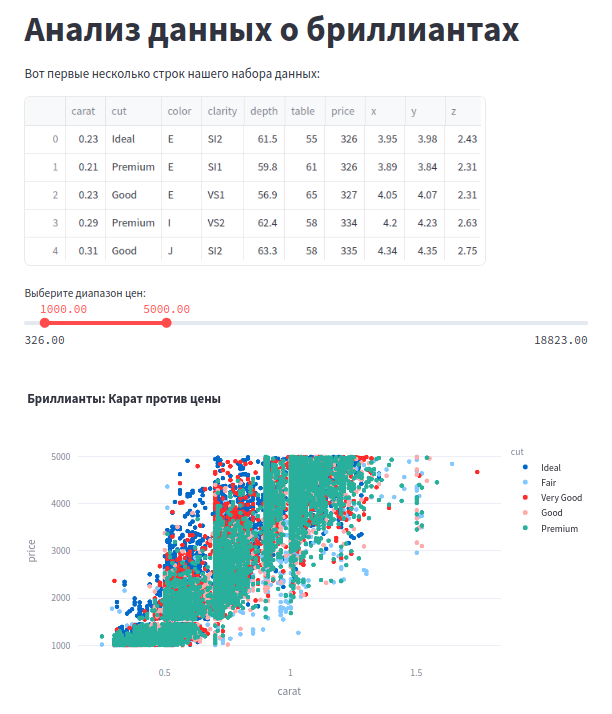
st.title("Анализ данных о бриллиантах")
# Отображаем первые несколько строк данных
st.write("Вот первые несколько строк нашего набора данных:")
st.write(data.head())
# Фильтрация по цене
price_range = st.slider("Выберите диапазон цен:", float(data['price'].min()), float(data['price'].max()), (1000.0, 5000.0))
filtered_data = data[(data['price'] >= price_range[0]) & (data['price'] <= price_range[1])]
# Визуализация данных
fig = px.scatter(filtered_data, x='carat', y='price', color='cut', title="Бриллианты: Карат против цены")
st.plotly_chart(fig)
Пример использования Streamlit для машинного обучения
Теперь давайте создадим простое приложение для прогнозирования цен на жилье с использованием модели машинного обучения. Мы будем использовать библиотеку Scikit-learn для создания модели.
- Создайте новый файл
ml_app.pyи добавьте следующий код:
import streamlit as st
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Загружаем данные
@st.cache
def load_data():
url = "https://raw.githubusercontent.com/ageron/handson-ml/master/datasets/housing/housing.csv"
data = pd.read_csv(url)
return data
data = load_data()
# Предобработка данных
data = data.dropna()
X = data[['median_income', 'total_rooms']]
y = data['median_house_value']
# Разделяем данные на тренировочные и тестовые наборы
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Создаем и обучаем модель
model = LinearRegression()
model.fit(X_train, y_train)
# Прогнозируем и оцениваем модель
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
# Заголовок приложения
st.title("Прогнозирование цен на жилье")
# Отображаем метрики модели
st.write(f"Среднеквадратичная ошибка модели: {mse}")
# Прогнозирование на основе пользовательского ввода
income = st.number_input("Введите средний доход населения:", value=3.0)
rooms = st.number_input("Введите общее количество комнат:", value=2000)
user_data = pd.DataFrame({'median_income': [income], 'total_rooms': [rooms]})
user_prediction = model.predict(user_data)
st.write(f"Прогнозируемая стоимость дома: ${user_prediction[0]:,.2f}")
Автоматическая перезагрузка
Streamlit автоматически перезагружает приложение при изменении кода. Это очень удобно, так как вам не нужно вручную обновлять браузер каждый раз, когда вы вносите изменения в скрипт. Ваше приложение всегда будет показывать актуальные данные.
Поддержка Markdown
Streamlit поддерживает Markdown, что позволяет легко форматировать текст и добавлять элементы, такие как заголовки, списки и ссылки. Например, вы можете использовать Markdown для написания документации прямо в вашем приложении.
st.markdown("""
# Заголовок первого уровня
## Заголовок второго уровня
- Пункт списка
- Ещё один пункт списка
""")
Интеграция с различными источниками данных
Streamlit может работать с различными источниками данных, такими как базы данных, API и файлы. Вы можете легко загружать данные и отображать их в вашем приложении.
import sqlite3
@st.cache
def load_data_from_db():
conn = sqlite3.connect('example.db')
df = pd.read_sql_query("SELECT * FROM table_name", conn)
conn.close()
return df
data = load_data_from_db()
st.write(data)
Магия слайдеров и интерактивности
Streamlit позволяет добавлять различные интерактивные элементы, такие как слайдеры, выпадающие списки, чекбоксы и другие виджеты. Это делает ваше приложение более интерактивным и удобным для пользователя.
import numpy as np
st.write("Интерактивный график синусоиды")
frequency = st.slider("Частота", 0.1, 10.0, 1.0)
x = np.linspace(0, 10, 100)
y = np.sin(frequency * x)
st.line_chart(y)
Поддержка кастомных тем
Вы можете настроить внешний вид вашего приложения, используя кастомные темы. Это позволяет вам создать уникальный стиль, который соответствует вашему бренду или предпочтениям.
Расширения и компоненты
Сообщество Streamlit активно разрабатывает расширения и компоненты, которые можно интегрировать в ваши приложения. Это могут быть сложные визуализации, формы обратной связи, карты и многое другое.
Деплой на облако
Streamlit предлагает встроенную поддержку деплоя приложений на облачные платформы, такие как Streamlit Sharing, Heroku, AWS и другие. Это позволяет вам легко делиться своими приложениями с миром.
Пример продвинутого приложения
Давайте создадим более сложное приложение, которое будет включать интерактивные элементы, загрузку данных из разных источников и кастомные визуализации.
import streamlit as st
import pandas as pd
import plotly.express as px
import numpy as np
# Загрузка данных из CSV
@st.cache
def load_csv_data():
url = "https://example.com/data.csv"
return pd.read_csv(url)
# Заголовок приложения
st.title("Продвинутое приложение Streamlit")
# Загрузка данных
data = load_csv_data()
st.write(data.head())
# Фильтрация данных
min_value = st.slider("Минимальное значение", float(data['column'].min()), float(data['column'].max()), float(data['column'].min()))
filtered_data = data[data['column'] >= min_value]
# Визуализация данных
fig = px.histogram(filtered_data, x='column', title="Гистограмма")
st.plotly_chart(fig)
# Интерактивный элемент
frequency = st.slider("Частота синусоиды", 0.1, 10.0, 1.0)
x = np.linspace(0, 10, 100)
y = np.sin(frequency * x)
st.line_chart(y)
Обработка пользовательского ввода
Streamlit предлагает множество виджетов для ввода данных пользователем. Вот несколько примеров:
- Текстовые поля и текстовые области:
user_name = st.text_input("Введите ваше имя")
st.write(f"Привет, {user_name}!")
user_message = st.text_area("Введите сообщение")
st.write(f"Ваше сообщение: {user_message}")
- Чекбоксы и радиокнопки:
agree = st.checkbox("Я согласен с условиями")
if agree:
st.write("Спасибо за согласие!")
option = st.radio("Выберите вариант", ('Вариант 1', 'Вариант 2', 'Вариант 3'))
st.write(f"Вы выбрали: {option}")
- Файловый загрузчик:
uploaded_file = st.file_uploader("Загрузите CSV файл", type="csv")
if uploaded_file is not None:
data = pd.read_csv(uploaded_file)
st.write(data.head())
Кастомные компоненты и расширения
Streamlit позволяет создавать и интегрировать собственные компоненты на базе JavaScript. Это открывает безграничные возможности для кастомизации и расширения функциональности.Пример использования кастомного компонента:
import streamlit.components.v1 as components
# Создание кастомного HTML компонента
components.html("""
<div style='background-color:lightblue; padding: 20px;'>
<h2>Привет, мир!</h2>
<p>Это кастомный HTML компонент.</p>
</div>
""")
Магия кэширования
Streamlit предоставляет декоратор @st.cache, который позволяет кэшировать результаты выполнения функций. Это особенно полезно при работе с большими наборами данных или при выполнении дорогостоящих вычислений.
@st.cache
def expensive_computation(a, b):
return a * b
result = expensive_computation(3, 4)
st.write(f"Результат: {result}")
Интерактивные карты
Streamlit поддерживает библиотеку pydeck для создания интерактивных карт. Это полезно для визуализации геопространственных данных.
import pydeck as pdk
# Данные для карты
data = pd.DataFrame({
'lat': [37.7749, 34.0522, 40.7128],
'lon': [-122.4194, -118.2437, -74.0060]
})
# Настройка карты
st.write("Интерактивная карта:")
st.pydeck_chart(pdk.Deck(
map_style='mapbox://styles/mapbox/light-v9',
initial_view_state=pdk.ViewState(
latitude=37.7749,
longitude=-122.4194,
zoom=10,
pitch=50,
),
layers=[
pdk.Layer(
'ScatterplotLayer',
data=data,
get_position='[lon, lat]',
get_color='[200, 30, 0, 160]',
get_radius=200,
),
],
))
Многостраничные приложения
Streamlit позволяет создавать многостраничные приложения, используя простую навигацию.
# Создаем простую навигацию
page = st.sidebar.selectbox("Выберите страницу", ["Главная", "Анализ данных", "Прогнозирование"])
if page == "Главная":
st.title("Главная страница")
st.write("Добро пожаловать на главную страницу!")
elif page == "Анализ данных":
st.title("Анализ данных")
# Здесь можно добавить код для анализа данных
elif page == "Прогнозирование":
st.title("Прогнозирование")
# Здесь можно добавить код для прогнозирования
Использование Streamlit для создания отчетов
Streamlit отлично подходит для создания интерактивных отчетов. Вы можете легко комбинировать текст, визуализации и интерактивные элементы в одном документе.
Пример создания интерактивного отчета:
st.title("Интерактивный отчет о продажах")
# Загрузка данных
data = pd.read_csv("sales_data.csv")
# Гистограмма продаж
st.subheader("Гистограмма продаж")
fig = px.histogram(data, x='sales', title="Распределение продаж")
st.plotly_chart(fig)
# Фильтрация данных по дате
st.subheader("Фильтрация данных по дате")
start_date = st.date_input("Начальная дата", value=pd.to_datetime("2023-01-01"))
end_date = st.date_input("Конечная дата", value=pd.to_datetime("2023-12-31"))
filtered_data = data[(data['date'] >= start_date) & (data['date'] <= end_date)]
st.write(filtered_data)
# Статистика по продажам
st.subheader("Статистика по продажам")
total_sales = filtered_data['sales'].sum()
average_sales = filtered_data['sales'].mean()
st.write(f"Общие продажи: {total_sales}")
st.write(f"Средние продажи: {average_sales:.2f}")
Streamlit - это мощный инструмент, который позволяет легко создавать интерактивные приложения для анализа данных и машинного обучения. Независимо от того, являетесь ли вы начинающим специалистом по данным или опытным исследователем, Streamlit поможет вам быстро и эффективно визуализировать и анализировать ваши данные. Попробуйте его в своих проектах и убедитесь сами, насколько это удобно!