Магия суммаризации текста: Как машинное обучение помогает нам усваивать информацию быстрее
В нашем мире информационного изобилия мы часто сталкиваемся с проблемой перегрузки информацией. Статьи, книги, отчеты - все это требует нашего внимания и времени на прочтение.
Но что если бы вы могли получить краткое содержание любого текста, сохраняя при этом все ключевые моменты? Вот где на помощь приходит суммаризация текста - и это то, о чем мы сегодня поговорим.

Введение в тему
Суммаризация текста - это процесс уменьшения длины текста, при котором сохраняются основные идеи и ключевые моменты. Однако выполнить это вручную может быть трудозатратным. Здесь на помощь приходит машинное обучение.

Машинное обучение может автоматизировать процесс суммаризации текста, преобразуя большие обьемы информации в удобные для чтения краткие обзоры. Это достигается путем обучения модели распознавать ключевые пункты и идеи в тексте и формулировать их в более сжатом виде.

Применение суммаризации текста огромно. Оно может помочь в образовательных целях, помочь сфокусироваться на ключевых моментах в длинных отчетах или даже помочь авторам проверить, насколько хорошо их идеи передаются в их тексте.

Вместе со всеми преимуществами, есть и сложности. Одна из них - это сохранение точности и контекста. Модель должна быть в состоянии понять не только ключевые моменты, но и их контекст, чтобы правильно сформулировать краткое содержание.

Суммаризация текста - это мощный инструмент, который, когда используется правильно, может значительно улучшить нашу способность усваивать информацию. И с помощью машинного обучения, это будет возможно на гораздо большем масштабе.
Простой пример на python
Для примера мы можем использовать библиотеку nltk в Python, которая предоставляет функции для обработки естественного языка.
Вот пример простой программы для суммаризации текста:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
def summarize_text(text):
# Загружаем стоп-слова
stop_words = set(stopwords.words("english"))
# Разбиваем текст на предложения
sentences = sent_tokenize(text)
# Составляем список слов, учитывая их частоту встречаемости
freq_table = dict()
for sent in sentences:
words = word_tokenize(sent)
for word in words:
if word not in stop_words:
if word in freq_table:
freq_table[word] += 1
else:
freq_table[word] = 1
# Вычисляем вес каждого предложения
sentence_weights = dict()
for sent in sentences:
for word, freq in freq_table.items():
if word in sent.lower():
if sent in sentence_weights:
sentence_weights[sent] += freq
else:
sentence_weights[sent] = freq
# Вычисляем средний вес предложения
avg_weight = sum(sentence_weights.values()) / len(sentence_weights)
# Формируем итоговую суммаризацию
summary = ''
for sent in sentences:
if sent in sentence_weights and sentence_weights[sent] > (1.2 * avg_weight):
summary += " " + sent
return summary
Вначале мы загружаем стоп-слова для английского языка. Стоп-слова - это общие слова, которые обычно не несут важного значения и могут быть исключены из текста (например, "a", "is", "the" и т.д.).
stop_words = set(stopwords.words("english"))Чтобы использовать стоп-слова для русского языка, достаточно поменять на:
stop_words = set(stopwords.words("russian"))Затем мы разбиваем входной текст на предложения и составляем таблицу частот встречаемости для каждого слова в тексте (исключая стоп-слова).
# Разбиваем текст на предложения
sentences = sent_tokenize(text)
# Составляем список слов, учитывая их частоту встречаемости
freq_table = dict()
for sent in sentences:
words = word_tokenize(sent)
for word in words:
if word not in stop_words:
if word in freq_table:
freq_table[word] += 1
else:
freq_table[word] = 1После этого мы вычисляем вес каждого предложения, суммируя частоты каждого слова, присутствующего в предложении.
# Вычисляем вес каждого предложения
sentence_weights = dict()
for sent in sentences:
for word, freq in freq_table.items():
if word in sent.lower():
if sent in sentence_weights:
sentence_weights[sent] += freq
else:
sentence_weights[sent] = freqЗатем мы вычисляем средний вес предложения.
# Вычисляем средний вес предложения
avg_weight = sum(sentence_weights.values()) / len(sentence_weights)Наконец, мы формируем итоговую суммаризацию, включая только те предложения, чей вес превышает 1.2 среднего веса.
# Формируем итоговую суммаризацию
summary = ''
for sent in sentences:
if sent in sentence_weights and sentence_weights[sent] > (1.2 * avg_weight):
summary += " " + sent
return summaryЭто очень простой алгоритм суммаризации и он может не всегда работать идеально. Для более сложных задач суммаризации вы можете рассмотреть использование методов машинного обучения и глубокого обучения.
Добавляем веб-интерфейс на streamlit
Установка Streamlit
Для начала, вам нужно установить streamlit, если у вас его еще нет. Это можно сделать с помощью pip:
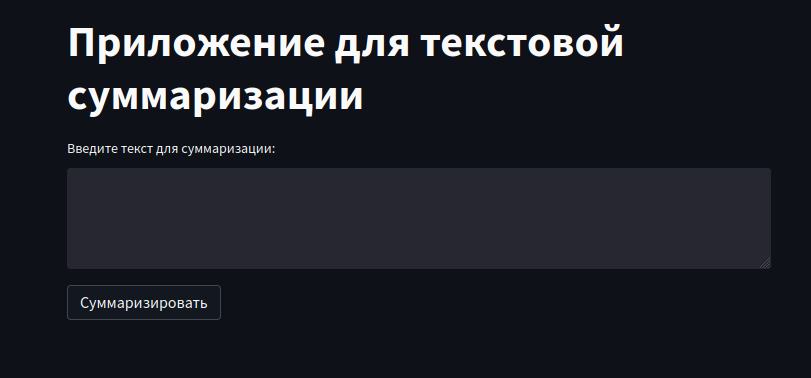
pip install streamlitСоздадим простой интерфейс, где пользователь может ввести текст для суммаризации в текстовую область, и при нажатии кнопки "Суммаризировать", текст передается в функцию summarize_text, которая генерирует суммаризацию. Ответ затем отображается под кнопкой.
Для этого достаточно будет импортировать саму библиотеке streamlit и инициализировать компоненты окна и кнопки:
import streamlit as st
# Streamlit приложение
def main():
st.title("Приложение для текстовой суммаризации")
text = st.text_area("Введите текст для суммаризации:")
if st.button("Суммаризировать"):
summary = summarize_text(text)
st.subheader("Суммаризация:")
st.write(summary)Полный код приложения будет выглядеть так:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
import streamlit as st
def summarize_text(text):
# Загружаем стоп-слова
stop_words = set(stopwords.words("english"))
# Разбиваем текст на предложения
sentences = sent_tokenize(text)
# Составляем таблицу частотности слов
freq_table = dict()
for sent in sentences:
words = word_tokenize(sent)
for word in words:
if word not in stop_words:
if word in freq_table:
freq_table[word] += 1
else:
freq_table[word] = 1
# Вычисляем вес каждого предложения
sentence_weights = dict()
for sent in sentences:
for word, freq in freq_table.items():
if word in sent.lower():
if sent in sentence_weights:
sentence_weights[sent] += freq
else:
sentence_weights[sent] = freq
# Вычисляем средний вес предложения
avg_weight = sum(sentence_weights.values()) / len(sentence_weights)
# Формируем итоговую суммаризацию
summary = ''
for sent in sentences:
if sent in sentence_weights and sentence_weights[sent] > (1.2 * avg_weight):
summary += " " + sent
return summary
# Streamlit приложение
def main():
st.title("Приложение для текстовой суммаризации")
text = st.text_area("Введите текст для суммаризации:")
if st.button("Суммаризировать"):
summary = summarize_text(text)
st.subheader("Суммаризация:")
st.write(summary)
if __name__ == "__main__":
main()Можете его скопировать, сохранить в файл app.py и запустить.
Обратите внимание, что это базовый пример и может быть дополнен дополнительными функциями и улучшениями в соответствии с вашими конкретными требованиями.
Запуск приложения Streamlit
Чтобы запустить приложение, сохраните код в файле .py, например app.py, и используйте следующую команду в терминале:
streamlit run app.pyПосле запуска, откроется новое окно в браузере и вы увидите наш созданный интерфейс на streamlit:
Если у вас возникнут вопросы на тему суммаризации, оставляйте комментарии к посту или в группе телеграмм канала https://t.me/nerditru