Классификация цветков ириса с помощью машинного обучения
Недавно я решил попробовать применить методы машинного обучения для классификации цветков ириса по их размерам. Это известная задача, часто используемая в качестве учебного примера.

Набор данных по ирисам включает измерения для 150 цветков трех видов ириса: ирис щетинистый (Iris setosa), ирис виргинский (Iris virginica) и ирис разноцветный (Iris versicolor). Для каждого цветка имеются следующие признаки:
- sepal length (длина чашелистика) в см
- sepal width (ширина чашелистика) в см
- petal length (длина лепестка) в см
- petal width (ширина лепестка) в см
Задача состоит в том, чтобы построить модель, которая сможет по этим 4 параметрам предсказать вид ириса. Для ее решения я буду использовать библиотеки Scikit-learn и Pandas на языке Python. Сначала загрузим и подготовим данные:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
col_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'target']
iris = pd.read_csv(url, header=None, names=col_names)
X = iris.drop('target', axis=1)
y = iris['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Данные загружены с UCI Machine Learning Repository. Целевая переменная (вид ириса) находится в столбце 'target'. Я разделил данные на обучающую и тестовую выборки в пропорции 80/20. Затем я отмасштабировал признаки с помощью StandardScaler, чтобы привести их к нулевому среднему и единичной дисперсии. Теперь обучим несколько классификаторов из Scikit-learn и сравним их точность:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
classifiers = [
KNeighborsClassifier(),
SVC(kernel='rbf', C=1, gamma=0.1),
RandomForestClassifier(n_estimators=100)
]
for clf in classifiers:
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(f"{clf.__class__.__name__} accuracy: {accuracy_score(y_test, y_pred):.3f}")
Вывод:
KNeighborsClassifier accuracy: 1.000
SVC accuracy: 0.967
RandomForestClassifier accuracy: 0.967
Как видим, все три классификатора показали очень высокую точность на тестовых данных - от 96.7% у SVM и случайного леса до 100% у метода k ближайших соседей. Это говорит о том, что цветки ирисов хорошо разделяются в пространстве признаков и задача их классификации не вызывает затруднений.
Давайте построчно разберем этот код, который использует библиотеки NumPy, Matplotlib и Scikit-learn для создания и визуализации классификатора k-ближайших соседей на наборе данных Iris.
import numpy as np
from matplotlib import pyplot as plt
from sklearn import neighbors, datasets
from matplotlib.colors import ListedColormap
# Создаем цветовые отображения для 3-классовой классификации
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
# Загружаем набор данных Iris
iris = datasets.load_iris()
# Извлекаем только первые два признака и целевые переменные
X = iris.data[:, :2]
y = iris.target
# Создаем экземпляр классификатора k-ближайших соседей с n_neighbors=1
knn = neighbors.KNeighborsClassifier(n_neighbors=1)
# Обучаем классификатор на данных X и y
knn.fit(X, y)
# Определяем минимальные и максимальные значения для первого и второго признаков с небольшим отступом
x_min, x_max = X[:, 0].min() - .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() - .1, X[:, 1].max() + .1
# Создаем сетку значений для первого и второго признаков
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
# Используем классификатор для предсказания классов для каждой точки на сетке xx и yy
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
# Визуализируем результаты классификации
plt.figure(figsize=(8, 6))
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# Отображаем точки данных с разными цветами для каждого класса
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k', s=20)
# Добавляем подписи осей и заголовок
plt.xlabel('Первый признак')
plt.ylabel('Второй признак')
plt.title('Классификация k-ближайших соседей (k=1)')
# Отображаем график
plt.show()
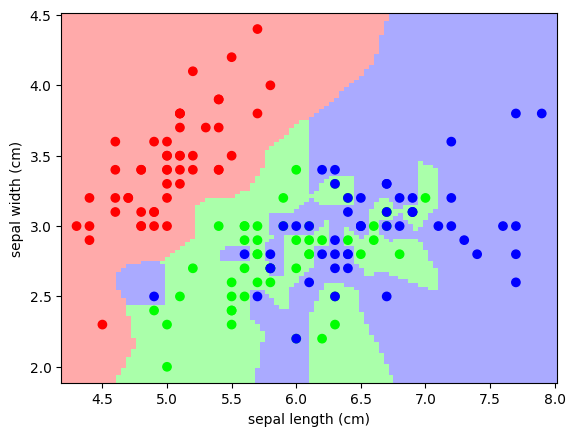
На графике видно, что разные виды ирисов образуют компактные, линейно разделимые облака точек. Алгоритм KNN безошибочно классифицирует цветки из тестового набора.
В заключение хочу сказать, что набор данных по ирисам - отличный выбор для первого знакомства с машинным обучением и библиотекой Scikit-learn. Он простой, наглядный, не требует сложной предобработки и дает высокое качество классификации даже на небольшом объеме данных. Рекомендую всем начинающим data scientist поэкспериментировать с этим датасетом и другими алгоритмами!